What is LLM evaluation? A practical guide to evals, metrics, and regression testing
LLM-powered applications can fail in unexpected ways. A customer support chatbot may provide accurate responses for weeks, then begin producing incorrect information after a model update. A RAG pipeline may retrieve the right documents but generate answers that contradict them. A small change to a prompt might improve the application's tone while breaking its accuracy on certain inputs.
These failures happen because teams deploy changes without measuring their impact on output quality. LLM evaluation provides a systematic way to test outputs against specific criteria, monitor quality over time, and identify problems before they affect users.
This guide explains what LLM evaluation is, its role in preventing production failures, and how to implement it effectively.
What is LLM evaluation?
LLM evaluation is the process of measuring how well an LLM or LLM-powered application performs against defined quality criteria. The process involves running the system against test cases, scoring outputs using automated or manual methods, and tracking performance over time to detect improvements or regressions.
LLM evaluation is not a single activity but a set of approaches that serve different purposes.
Offline vs. online evaluation
Two different evaluation modes serve different purposes in the development lifecycle.
Offline evaluation runs during development on curated datasets before deployment. Teams test prompt changes, model swaps, or retrieval modifications using known inputs and measure whether the changes improve or degrade quality. Offline evaluation functions, such as unit or integration testing in traditional software, provide a safety net that catches problems before they reach production.
Online evaluation monitors live traffic in production. Scoring runs asynchronously on sampled requests, tracking quality metrics alongside operational metrics like latency and error rates. Online evaluation catches issues that offline testing cannot anticipate, including novel user queries, distribution shifts, and gradual model drift.
The best teams use both offline and online evaluation to validate changes before release and detect regressions in real production traffic.
Component-level vs. end-to-end evaluation
Component-level evaluation isolates individual components of the system, such as retrieval quality in a RAG pipeline or tool-selection accuracy in an agent. End-to-end evaluation measures whether the complete system achieves the user's goal. When end-to-end scores drop, component-level scores reveal where the problem originated.
Even with the right scope, teams often confuse model performance with product performance.
Model evaluation vs. product evaluation
Model evaluation measures raw LLM capabilities across standardized tasks. Product evaluation measures whether the system solves actual user problems. High benchmark scores do not guarantee that the system will perform well on domain-specific tasks with real-world constraints. Teams building production applications need product evaluation that reflects their specific use cases.
What to evaluate in LLM applications
Failures in LLM applications often originate in specific components, not the system as a whole. Effective evaluation examines each component that can degrade output quality.
Prompt evaluation: Prompt changes represent the most common source of regressions. A wording adjustment that improves one type of query can silently degrade another. Prompt evaluation compares outputs before and after changes across representative test cases, assessing whether the modification improves overall performance or introduces new failure modes.
Retrieval and generation evaluation (RAG pipelines): RAG pipelines require evaluation across multiple stages. Retrieval evaluation measures whether the system finds relevant documents for a given query. Generation evaluation assesses whether the LLM produces outputs grounded in the retrieved context, without hallucinating information unsupported by the documents. Poor retrieval quality limits what even the best generation can achieve, so evaluating both stages separately reveals where failures originate.
Agent evaluation: Agents introduce multi-step complexity, in which errors in early decisions compound across subsequent steps. Agent evaluation must track task completion rates, tool-selection accuracy, argument-construction quality, and execution efficiency. A trace that shows every decision the agent made during execution enables debugging when end-to-end scores drop.
Fine-tuned model evaluation: Fine-tuned models should be evaluated against both the target task and baseline performance. Fine-tuning can improve specific behaviors while degrading general performance, a phenomenon called catastrophic forgetting. Evaluation must verify that improvements in the target domain do not come at the cost of regressions elsewhere.
Routing and orchestration evaluation: Routing and orchestration systems that direct queries to different models or components need evaluation of decision quality. Misrouting a complex query to a lightweight model produces poor outputs even when both the routing logic and the model work correctly in isolation.
Safety evaluation: Safety evaluation measures whether outputs comply with organizational policies, avoid toxic content, resist prompt injection attacks, and treat different user groups fairly. Safety failures can cause significant harm even when task-completion metrics appear healthy.
Building an evaluation workflow for LLMs
A complete evaluation workflow connects datasets, scoring criteria, evaluators, thresholds, and CI/CD integration into a feedback loop that improves quality over time.
Dataset construction forms the foundation. Test cases must include happy-path scenarios that exercise normal functionality, edge cases that stress boundary conditions, adversarial inputs that attempt to break the system, and off-topic requests that the system should decline. Coverage across these categories provides more value than raw volume. Teams building datasets can draw from production traffic where possible, since real user queries reveal patterns that synthetic examples miss.
Rubric definition specifies what "good" means for each quality dimension. Vague criteria like "be accurate" provide no guidance. Actionable criteria like "cite sources from the provided context and do not claim facts that the documents do not support" enable consistent scoring. Each rubric should enumerate specific conditions for success and failure so that different evaluators apply the same standards.
Evaluator selection depends on what the rubric measures. Code-based scorers handle deterministic checks like format validation, length constraints, and schema compliance. These scorers run quickly, cost nothing, and produce reproducible results. LLM-as-a-judge scorers handle nuanced criteria that code cannot capture, such as tone, helpfulness, and whether a response truly addresses the underlying intent of a question. Human evaluation provides ground-truth calibration and detects issues that automated methods miss, though it is more expensive and scales less well.
Scoring and aggregation combine individual evaluations into actionable signals. A single metric rarely captures overall quality. An answer can be factually correct but miss what the user actually asked, or be relevant but fabricate supporting details. Most teams track multiple metrics covering accuracy, relevance, safety, and operational efficiency, then aggregate them into composite scores or dashboards that surface problems.
Threshold setting defines acceptance criteria for deployment. Thresholds must reflect minimum acceptable quality based on real-world requirements. Thresholds that fail constantly provide no signal, while thresholds that fail only on genuine regressions enable confident iteration.
CI/CD integration automates the workflow so that every code change triggers evaluation. Pull requests that would reduce quality below thresholds fail automatically, preventing regressions from reaching production. The pipeline should report which test cases improved, which regressed, and by how much, giving developers the information they need to iterate.
LLM evaluation metrics
Metrics fall into several categories based on what they measure and how they are implemented.
Task success metrics
Task success metrics measure whether the system achieved the user's goal. Task completion rate answers the most basic performance question. Correctness verifies that outputs contain accurate information. Following the instructions confirms that the system adhered to the constraints specified in the prompt.
Factuality and groundedness metrics
Factuality and groundedness metrics measure whether outputs stick to verifiable information. Faithfulness scores whether claims in the output can be traced back to the provided context, catching hallucinations where the model invents information. Groundedness measures the degree to which every statement has support in source documents. These metrics are essential for RAG applications and any system that should not fabricate information.
Relevance metrics
Relevance metrics measure alignment between outputs and inputs. Answer relevance scores whether the response addresses what the user actually asked. Context relevance in RAG systems measures whether retrieved documents relate to the query, since irrelevant retrieval limits generation quality.
Safety metrics
Safety metrics cover toxicity detection, bias measurement, and policy compliance. Toxicity scorers flag harmful language, while bias scorers surface differences in system behavior across user groups. Policy adherence evaluation then verifies that outputs comply with organizational rules on permitted and prohibited content.
Style and tone metrics
Style and tone metrics measure subjective qualities like brand voice adherence, formality level, and clarity. These metrics require LLM-as-a-judge implementation since code-based rules cannot capture subtle stylistic qualities.
Operational metrics
Operational metrics track latency, token cost, and throughput. Fast, cheap outputs that fail quality checks waste resources, whereas slow, expensive outputs that pass quality checks may not be viable for production. Operational metrics constrain the space in which quality metrics must be optimized.
Reference-based and reference-free metrics
Reference-based and reference-free metric differences affect dataset requirements. Reference-based metrics compare outputs against expected answers, requiring labeled ground truth. Reference-free metrics evaluate outputs independently, enabling evaluation when ground truth is unavailable or multiple correct answers exist.
Running regression testing for LLM applications
Regression testing prevents changes from breaking existing functionality. LLM regression testing adapts traditional software testing concepts to handle non-deterministic outputs and subjective quality criteria.
Golden sets are curated collections of test cases representing critical functionality. Each golden set case includes an input, an optional expected output or reference, and scoring criteria. Golden sets should cover the most important use cases, known failure modes from past incidents, and edge cases discovered through production monitoring. Teams start with 25 to 50 cases and expand as they discover new failure patterns.
Building golden sets requires balancing stability against freshness. Stable test cases provide consistent regression detection, but stale cases that no longer represent real usage patterns create false confidence. Teams should version golden sets alongside code and refresh them regularly with cases drawn from production traffic.
Drift detection catches gradual quality degradation. Prompt drift occurs when small wording changes accumulate until the prompt behaves differently than intended. Model drift occurs when upstream provider updates change model behavior without any changes to the application code. Regular evaluation runs detect drift by comparing current scores against historical baselines.
Flaky evaluations arise in LLM testing because identical inputs can produce different outputs. Temperature settings control output randomness, and setting temperature to zero produces more deterministic results for test cases that need reproducibility. For inherently variable outputs, statistical approaches aggregate scores across multiple runs to separate signal from noise. Confidence intervals quantify uncertainty, and sample sizes should be large enough to detect meaningful differences.
Release criteria define the conditions that must be met before deployment proceeds. Criteria include minimum scores on key metrics, no regressions beyond a tolerance threshold compared to the current production version, and all safety checks passing. Ambiguous criteria lead to debates during release time, so teams should establish explicit pass/fail rules in advance.
The feedback loop between production and development closes when production failures become test cases. A query that exposes a failure mode in production should be added to the golden set immediately, preventing the same failure from recurring after a fix ships.
Avoiding common pitfalls in LLM evaluation
The table below summarizes common failure patterns in LLM evaluation, explains why they occur, and outlines how teams can fix them.
| Pitfall | What goes wrong | Why it happens | How to fix |
|---|---|---|---|
| Overfitting to eval sets | Scores improve on test cases without real-world quality gains | Teams repeatedly optimize prompts or models against a fixed set of examples | Regularly refresh eval datasets with new production cases and keep a holdout set that is never optimized against |
| Judge bias | Evaluators consistently favor certain outputs regardless of true quality | LLM judges exhibit position bias, verbosity bias, or self-model bias | Randomize ordering, use multiple judge models, and calibrate against a small human-labeled gold set |
| Data leakage | Evaluation scores are inflated and fail to reflect generalization | Test cases overlap with training data or public benchmarks | Use private datasets, rotate test cases, and version evaluation data separately from training data |
| Metric gaming | Systems optimize for metrics without becoming more useful to users | Models learn to exploit scoring shortcuts rather than improve behavior | Track multiple diverse metrics and review trade-offs instead of optimizing a single score |
| Ignoring edge cases | Systems fail on the inputs that users eventually send | Evaluation focuses only on happy-path scenarios | Add adversarial testing, red-teaming, and edge cases discovered in production |
| Vibes-based evaluation | Quality decisions rely on intuition instead of evidence | Lack of systematic measurement and historical baselines | Establish consistent metrics, track trends over time, and use data to compare alternatives |
Systematic evaluation replaces intuition with evidence, enabling teams to detect drift, compare alternatives objectively, and allocate resources based on data.
How Braintrust helps teams run LLM evaluations in real time
Braintrust brings dataset management, scoring, tracing, CI/CD integration, and production monitoring together in a single platform to easily implement the best LLM evaluation practices.
Evaluation infrastructure
Evaluation runs: Test prompts and models against datasets using configurable scorers. The autoevals library includes pre-built scorers for factuality, relevance, and safety, while custom scorers handle domain-specific criteria. Running an evaluation creates an experiment that displays results in the terminal and populates the web interface for detailed analysis.
Dataset management: Store golden sets with versioning and collaborative editing. Teams build datasets from production logs, expert curation, or synthetic generation. When production monitoring surfaces a failure, adding that case to a dataset takes one click, closing the loop between production incidents and regression tests.
Prompt and workflow management
Prompt management: Version, organize, and collaborate on prompts with built-in version control. Track changes over time, compare different versions, and ensure teams work from the same prompt templates. Prompts can be managed directly in the UI or through the SDK.
Playground: Rapidly prototype and test prompts, models, and scorers in an interactive no-code workspace. Run full evaluations in real-time, compare multiple variants side-by-side to see exactly what changed, and share configurations with teammates. The playground enables A/B testing of prompt changes against golden datasets before deployment.
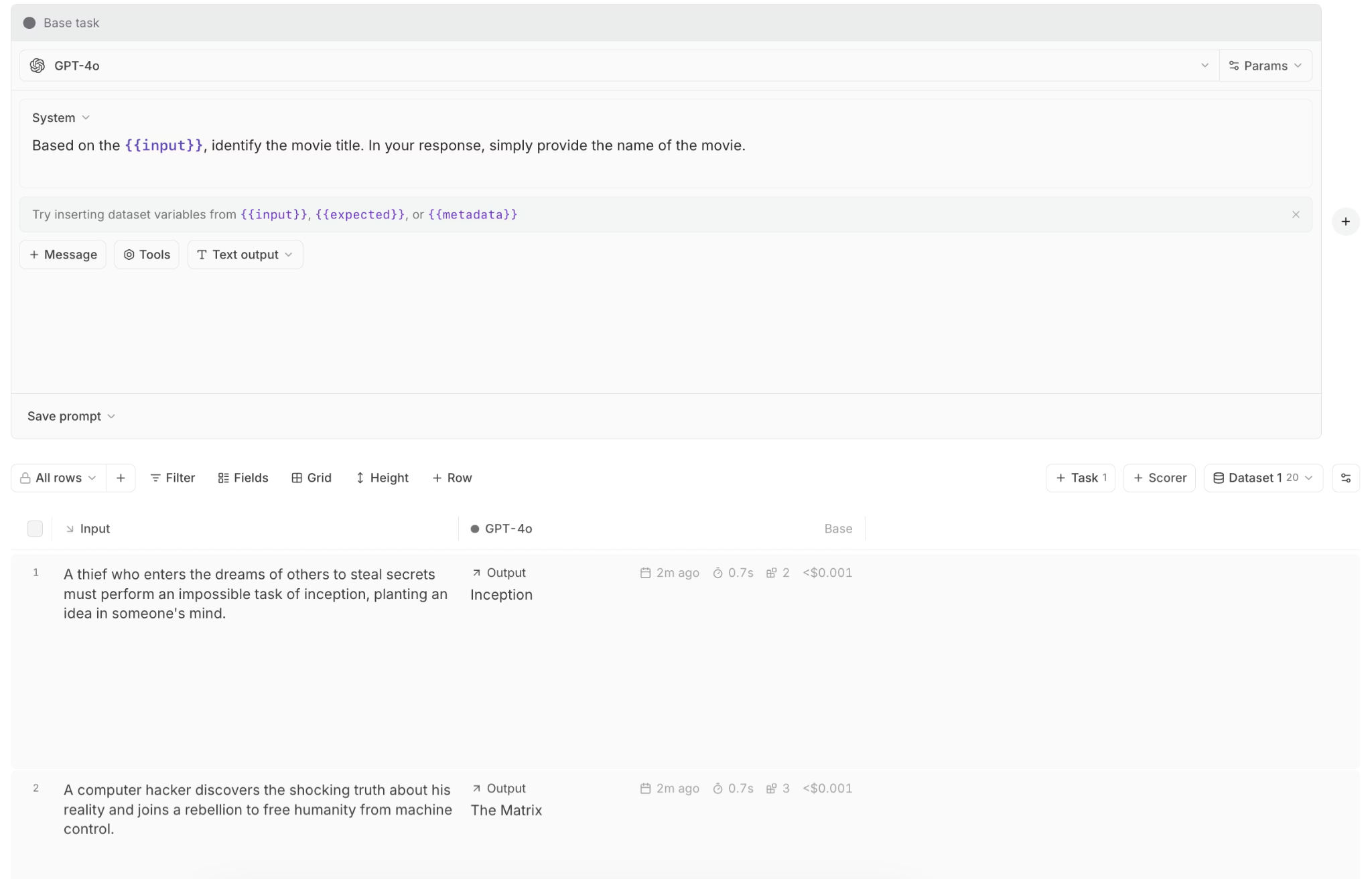
Debugging and observability
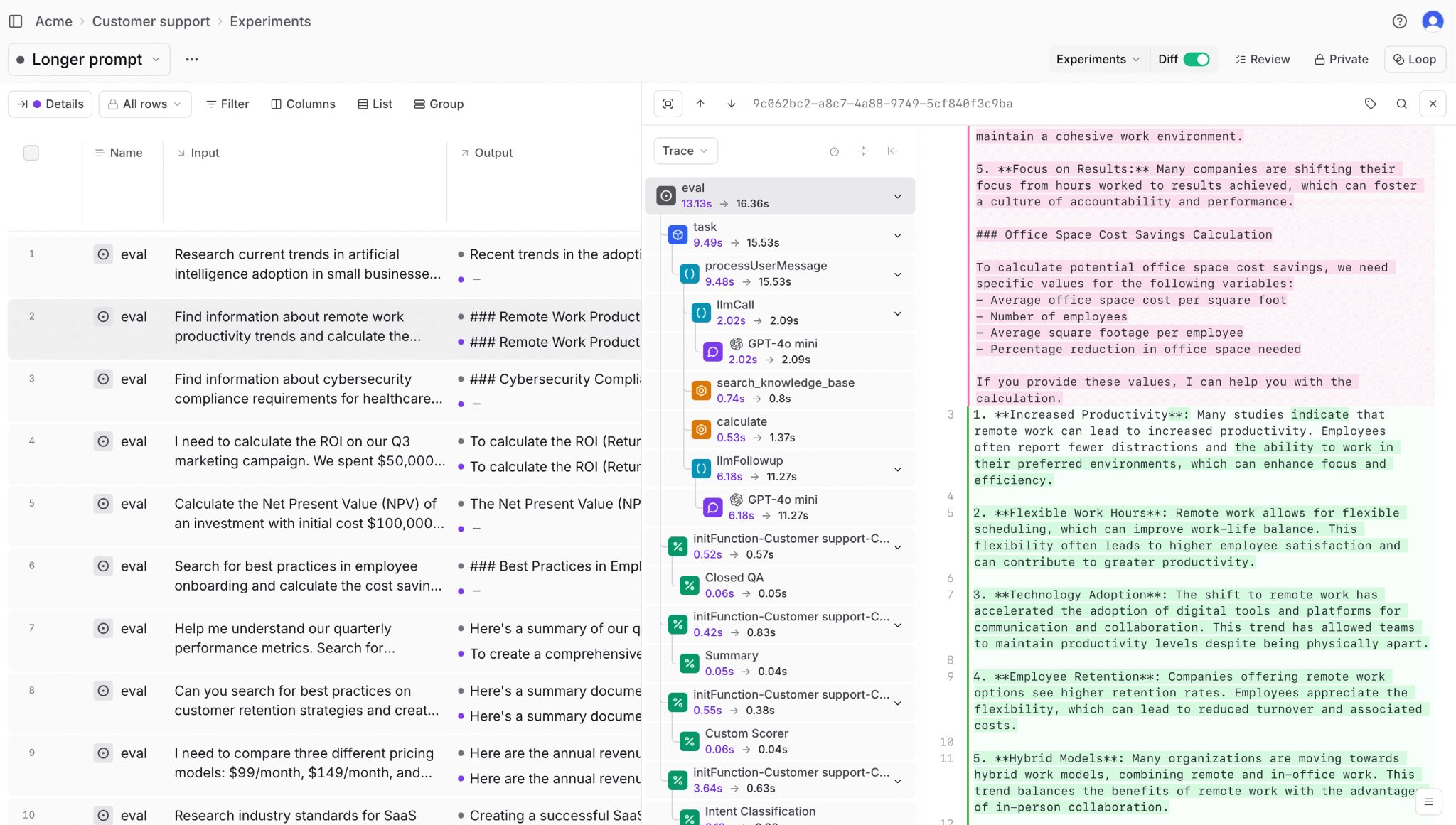
Tracing and debugging: Capture every decision during execution with duration, token counts, cost estimates, and errors broken down by type. The trace viewer displays spans as an expandable tree, enabling developers to drill from a failed score down to the specific step that caused the failure. Traces work consistently across offline evaluation and production logging, so debugging happens in the same interface regardless of where the issue surfaced.
Production monitoring: Score live traffic with configurable sampling rules. Dashboards track quality metrics alongside operational metrics like latency and cost. Alerts trigger when scores drop below thresholds, catching regressions before user complaints accumulate.
Brainstore: Store and analyze AI application logs in a database built for AI workflows. Query, filter, and review logs faster than traditional databases. Brainstore queries and filters AI traces faster than traditional databases, enabling instant analysis of production data.
Workflow automation
CI/CD integration: Run evaluation suites on every pull request through a native GitHub Action. Results post as PR comments showing test case improvements and regressions. The pipeline blocks deployments that would reduce quality below thresholds, preventing regressions from reaching production.
Loop AI assistant: Automate the most time-intensive parts of AI development. Loop analyzes production logs to identify failure patterns, generates test datasets from real user interactions, creates custom scorers from natural language descriptions, and helps iterate on prompts with full project context. Product managers can describe requirements in plain English, and Loop produces working scorers without code.
Teams at Notion, Stripe, Zapier, Instacart, and Vercel use Braintrust for production AI evaluation. Notion's product team increased its issue-resolution rate from 3 fixes per day to 30 after implementing systematic evaluation with Braintrust.
Ready to build reliable LLM applications? Get started with Braintrust's free tier, which includes 1 GB of processed data and 10,000 evaluation scores per month.
Conclusion
LLM evaluation helps teams move from reacting to problems to preventing them. Instead of discovering issues through user complaints or production incidents, you can catch failures during development and ship changes with confidence.
Getting started with LLM evaluation doesn't require a complex setup. Choose two or three metrics that matter most for your application, build a small golden set from real user queries, and run an initial evaluation to understand your baseline. Once you have this foundation, integrate evaluation into your development workflow so it runs automatically with every change, and monitor production behavior to turn new failure cases into test cases, creating a reliable feedback loop over time.
Each issue discovered in production strengthens future testing, each metric adds clarity around quality, and your system becomes more stable and better with every iteration, aligned with how users actually interact with it.
Braintrust lets you evaluate changes before release, trace failures when scores drop, and monitor production quality in one system, so you can identify which change caused a drop and prevent problematic deployments from reaching users. This visibility enables faster progress without sacrificing quality. Start evaluating with Braintrust before regressions reach your users.
FAQs: LLM evaluation guide
What is LLM evaluation?
LLM evaluation is the process of verifying whether your AI application is performing as intended. Think of it like quality control for AI outputs. You provide your system with test questions, check the answers it produces, and assess whether they meet your standards for accuracy, relevance, and usefulness. The key difference from testing conventional software is that AI doesn't always produce the same output twice, and a "good answer" often depends on context rather than a single right answer.
What is the difference between offline and online LLM evaluation?
Offline evaluation checks quality before changes are released. Teams test updates using a fixed set of example questions to make sure nothing breaks when prompts, models, or retrieval logic change.
Online evaluation checks the quality after the system is live. It analyzes real user interactions to detect issues that don't appear in test cases, such as new question patterns, edge cases, or gradual performance drops.
What tools do I need for LLM evaluation?
A complete LLM evaluation setup requires dataset management for storing and versioning test cases, scorers that measure quality dimensions relevant to your application, tracing infrastructure that captures model inputs and outputs for analysis, CI/CD integration that runs evaluations automatically on code changes, and production monitoring that scores live traffic and alerts when quality degrades. Braintrust provides all of these capabilities in a unified platform, eliminating the need to use separate tools for each function.
How do I get started with LLM evaluation?
Start by collecting 25 to 50 test cases from production traffic or realistic scenarios that represent your most important use cases and known failure modes, define 2 to 3 metrics that capture the quality dimensions you care about most, and run your first evaluation to establish baseline scores before making changes. Braintrust offers a free tier with 1 GB of processed data and 10,000 evaluation scores per month, which provides enough capacity to build your evaluation workflow and prove its value before scaling up.